AWS Glue StudioでDynamoDBのデータをRedshift Serverlessに登録してみた
ベンジャミンのクワバラです。
Amplifyで構築された本番稼働中のWebサイトに分析基盤を新しく用意したので、そのナレッジを紹介します。
WebサイトではデータベースにDynamoDBを採用していて、ユーザテーブル、ユーザへの質問テーブル、ユーザのアンケート回答テーブルといった感じでテーブルが複数に分散していました。
DynamoDBはテーブルを結合するクエリがないため、データを分析するためには複数DynamoDBのデータをローカルにダウンロードして結合させるなどの加工処理が必要になり、分析の度に毎回時間をかけて処理をするといった課題がありました。
その課題を解決するためにQuicksight+Redshift Serverless+Glueを利用して分析基盤を構築しました。
今回はDynamoDBのデータをGlueを利用してRedshift Serverlessに登録するまでの方法を紹介します。
【事前作業】
- DynamoDBが構築済みで、データがセットされていること
- Redshift Serverlessが構築済みで、データベース/スキーマ/テーブルが用意されていること
- Glue Connectorが構築済みで、Redshift Serverlessに繋がること
- Glue crawlerでDynamoDBテーブルをスキャンし、Glue tableが構築されていること
準備することが多いですが、今回はAWS Glue Studioの手順にフォーカスするためスキップしました。もし要望があれば後日紹介するかもしれません。
【AWS Glue Studio構築手順】
1.Visual ETLをクリック

2.SourceでAmazon DynamoDBを選択
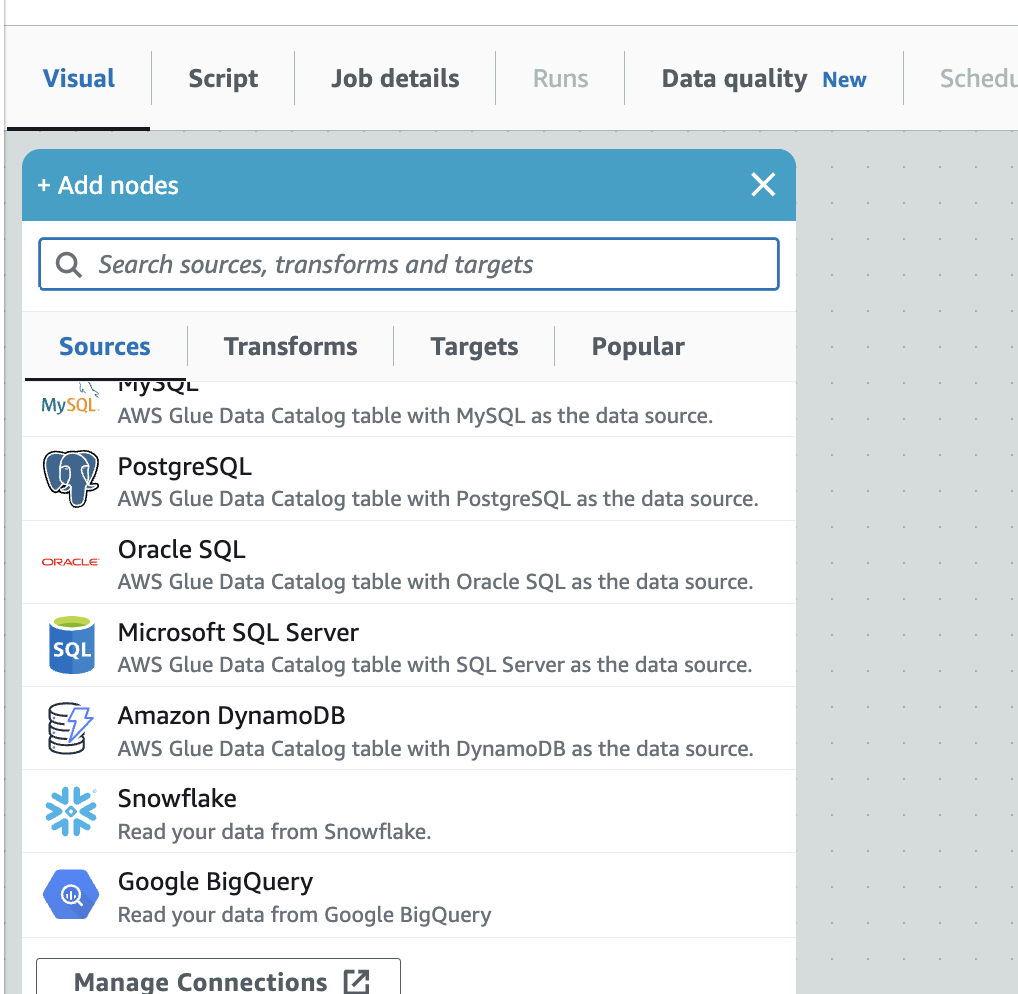
3.プロパティを開き、Glueのデータベースとテーブルをセット

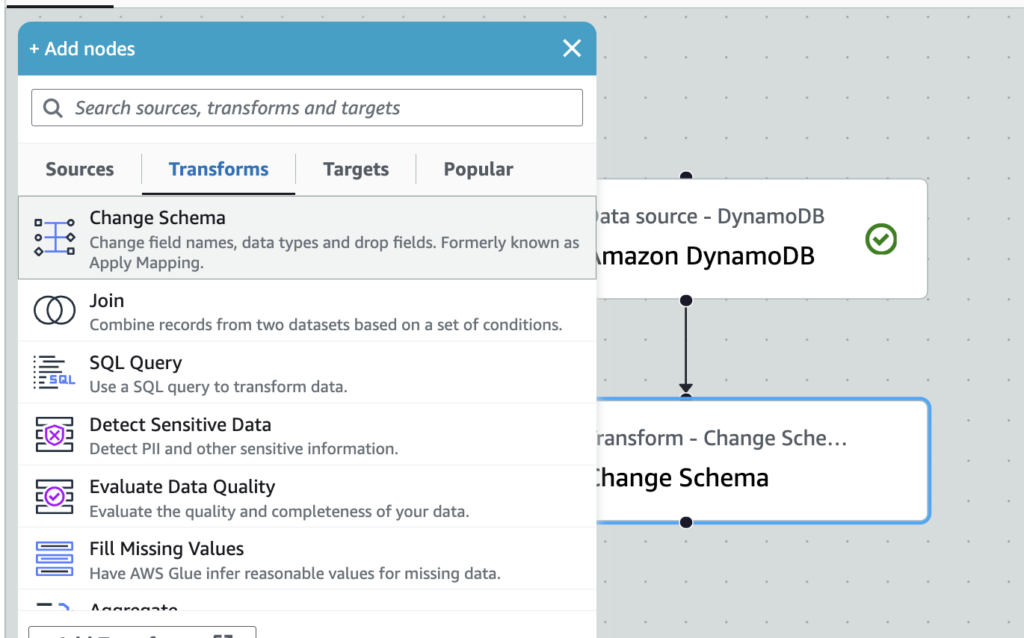
4.Add nodes(左上の➕ボタン)をクリックし、Change Sehemaをクリック
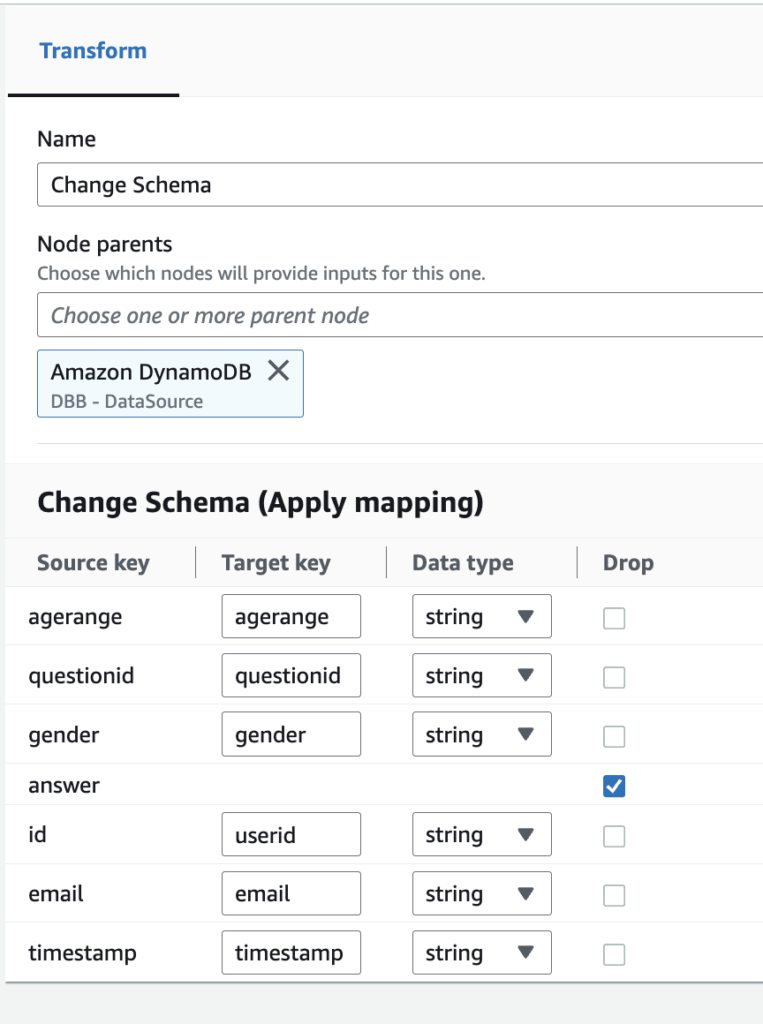
5.プロパティからRedshift Serverlessにデータが流せるようにスキーマを設定(answer列にはJsonデータが入っているためDropとしました)
6.Add nodes(左上の➕ボタン)をクリックし、Amazon Redshiftをクリック
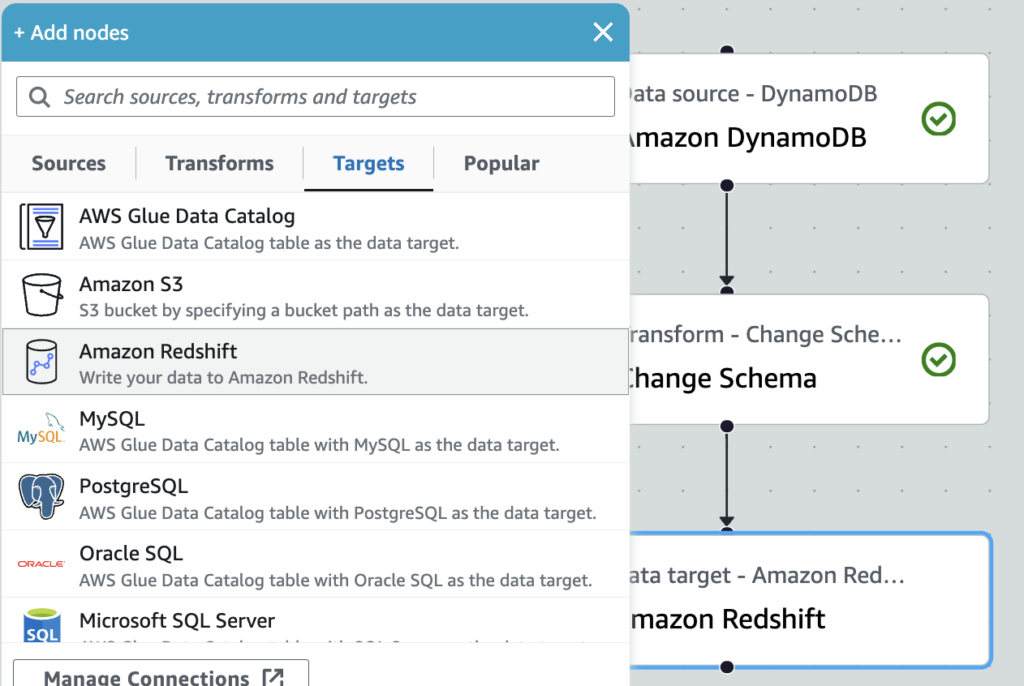
7.プロパティで各種情報を入力
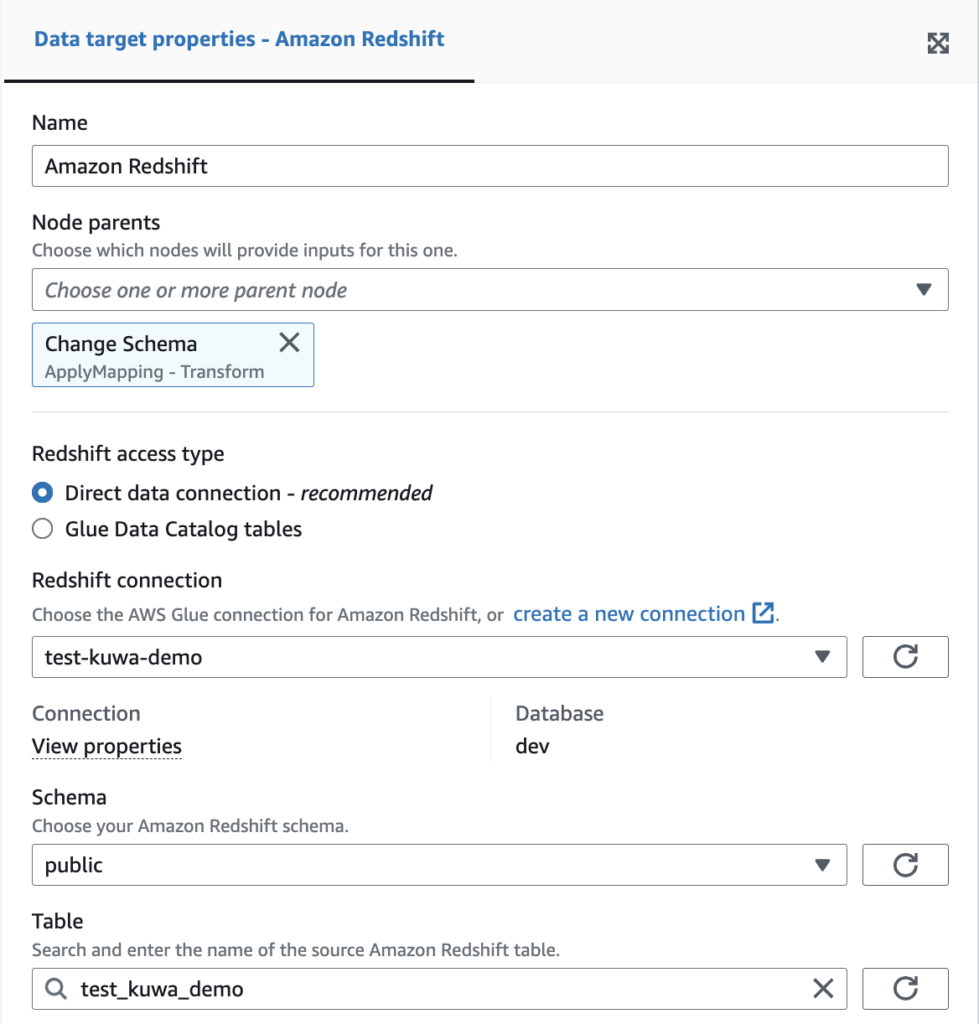
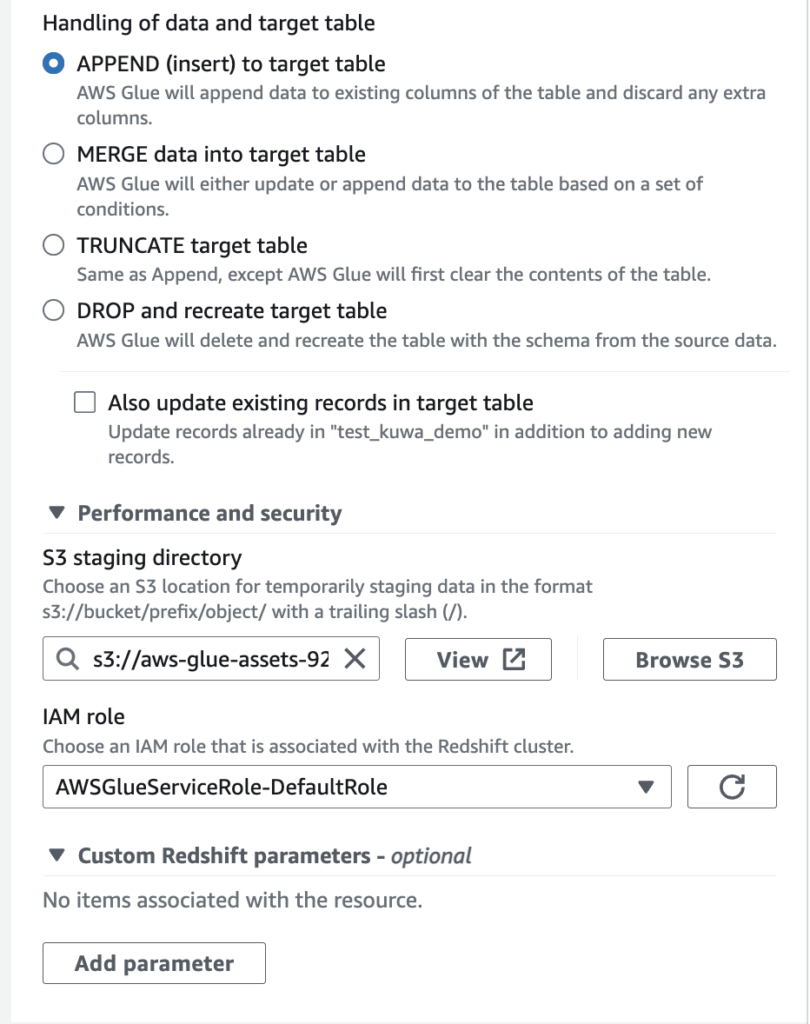
8.ジョブ名を入力してSave。するとJob detailsに赤く①と表示されるのでクリック。

9.IAM Roleにロールをセット(IAMロールを事前に作成しておく必要があります)

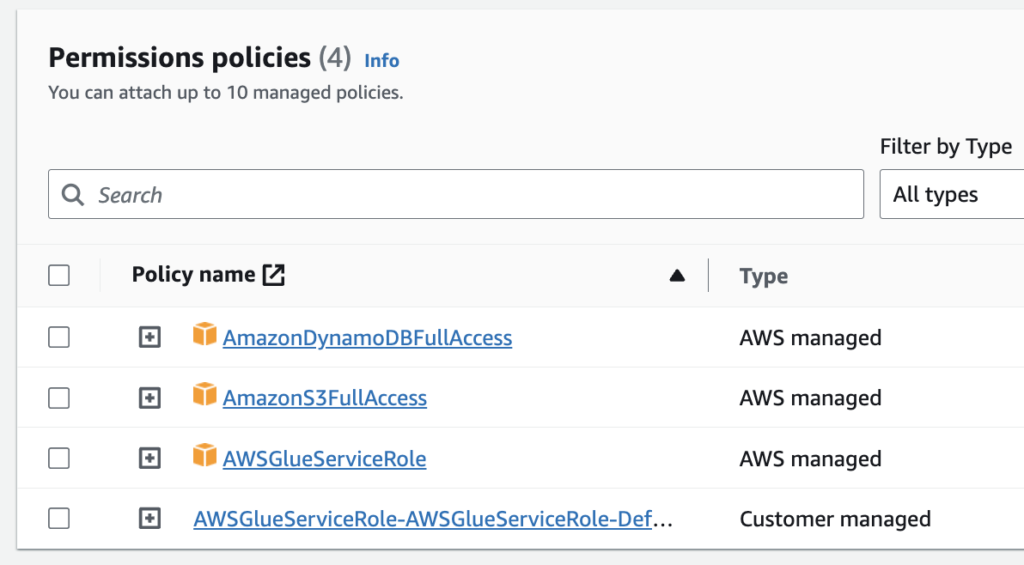
10.SaveしてRunボタンをクリック

11.Job run monitoringからGlueジョブが成功していることを確認(苦労の跡が・・)
12.Redshift ServerlessのQuery Editorにログインし、テーブルにデータが登録されていることを確認

以上がAWS Glue EditorでDynamoDBのデータをRedshift Serverlessに登録するまでの手順になります。
今回の分析基盤を構築するメンバーはインフラメンバーのみのため、プログラムに慣れていないメンバーが多いという背景があります。そのためLambdaは利用せずにノーコードで実現したいという狙いもあり、AWS Glue Editorを採用しました。
AWS Glue EditorはAWSコンソールからノーコードで実現できるところがメリットですが、Job monitorに表示されるエラー内容が非常にシンプルな表現の時があり、何が原因なのか、どこを調査すれば良いのか分からずにハマることがあります。ご注意ください。
Amplifyを採用したシステムではシステムリリース後に機能追加要望があった場合、DynamoDBを利用しているためにDBのカスタマイズが難しく、要望への対応に苦労するケースがあるようです。その場合にこのDynamoDB+Glue+Redshiftを追加するのも有用かなと考えています。